AI自动化个人知识库搭建流程
使用AI搭建LLKwiki–AI时代下个人知识自动管理
1. 为什么使用Obsidian?
个人知识库的搭建为什么使用Obsidian?明明有更多的选择,像Notion,印象笔记等等
Obsidian最大的优势在于
- 完全本地化,全部都是
md文档,不怕云端的丢失 - 支持双向链接,可以方便的进行知识之间的关联
- 丰富的插件系统,多到你会忘记自己学习Obsidian的初衷
如何快速入手Obsidian,可以参考Obsidian入门
Obsidian最大的优势就是使用AI能自动帮你关联到相关的知识点和笔记;能够关联到相关的应用等方面,让你的知识不再是孤岛,而是连成一片
2. Claude Code最佳搭档
在Claude Code发展到现在之前,Obsidian就像VSCode一样,AI仅仅是作为插件辅助笔记的生成和管理,而Claude Code的出现,让Obsidian真正变成了一个AI时代下的知识库。
Claude Code 则是一个强大的 AI 编译器与自动化引擎。它能理解自然语言指令,读写本地文件系统,执行复杂的自动化任务。它的设计和 Obsidian 的本地存储模式天然契合——一个文件夹一个workspace
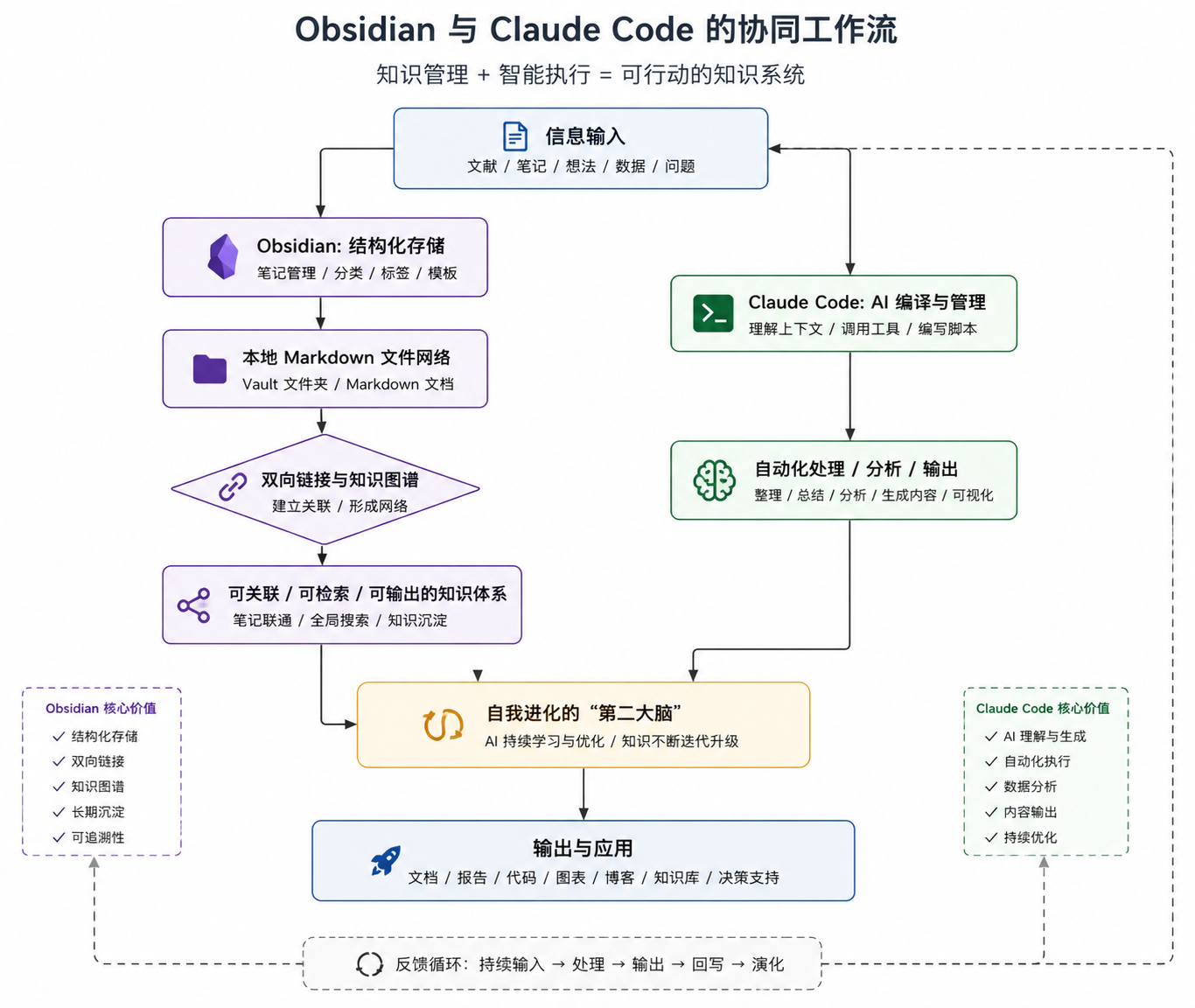
Claude Code与Obsidian结合,就像是VSCode与Git的结合,Claude Code负责AI的执行,Obsidian负责文档的存储和展示
- Obsidian 负责”结构化存储与可视化网络”
- Claude Code 负责”AI 编译与自动化管理”
Obsidian是仓库,Claude是大脑,搭建成完整的思考系统
系统优势:
- 告别信息碎片化。 所有零散的信息都会被”编译”成相互关联的原子化知识单元
- 全流程自动化。 从信息收集、处理、分类、链接到结构化输出,大部分繁琐工作都由 AI 代劳,人适合做决策和判断
- 构建可生长的体系。 知识库不再是静态的仓库,而是一个能够通过 MOC(主题地图)和持续链接自我进化的有机体
- 成为高效”超级个体”。 知识高效转化为文章、报告、方案,提升个人输出与决策质量
3. 环境搭建
3.1 Obsidian 安装
Obsidian的安装请查看这篇安装教程和入门使用,帮助你快速了解Obsidian
3.2 Claude Code安装
Claude Code的安装和套餐API配置请看claude code安装教程,同样claude code使用,skill使用等等,请各自查看
传统的AI+笔记的方式,通常是
- 复制一段内容
- 打开网页/CHat客户端
- 让AI帮你总结、改写等
- 再粘贴回来
Claude Code + Skills:
- 调用技能 skills
- 能执行复杂指令(重写、拆解、结构化、补充)
- 作为你的协作伙伴,Claude 只是参与编辑,整理不改变你本身的原始数据
3.3 Claudian插件安装
Obsidian最强大但同样最让人忘记初衷的地方就是插件市场
在设置中选择第三方插件,然后关闭安全模式,即可打开三方插件市场
- 手动安装
可以选择手动下载这些插件的安装包,然后手动放置在 obsidian 笔记仓库中的 .obsidian/plugins 文件夹下,这种比较繁琐,核心就是要放对位置
- 从github下载最新版本
- 创建文件夹,解压文件
- 复制到
.obsidian/plugins目录下
- BRAT 插件安装
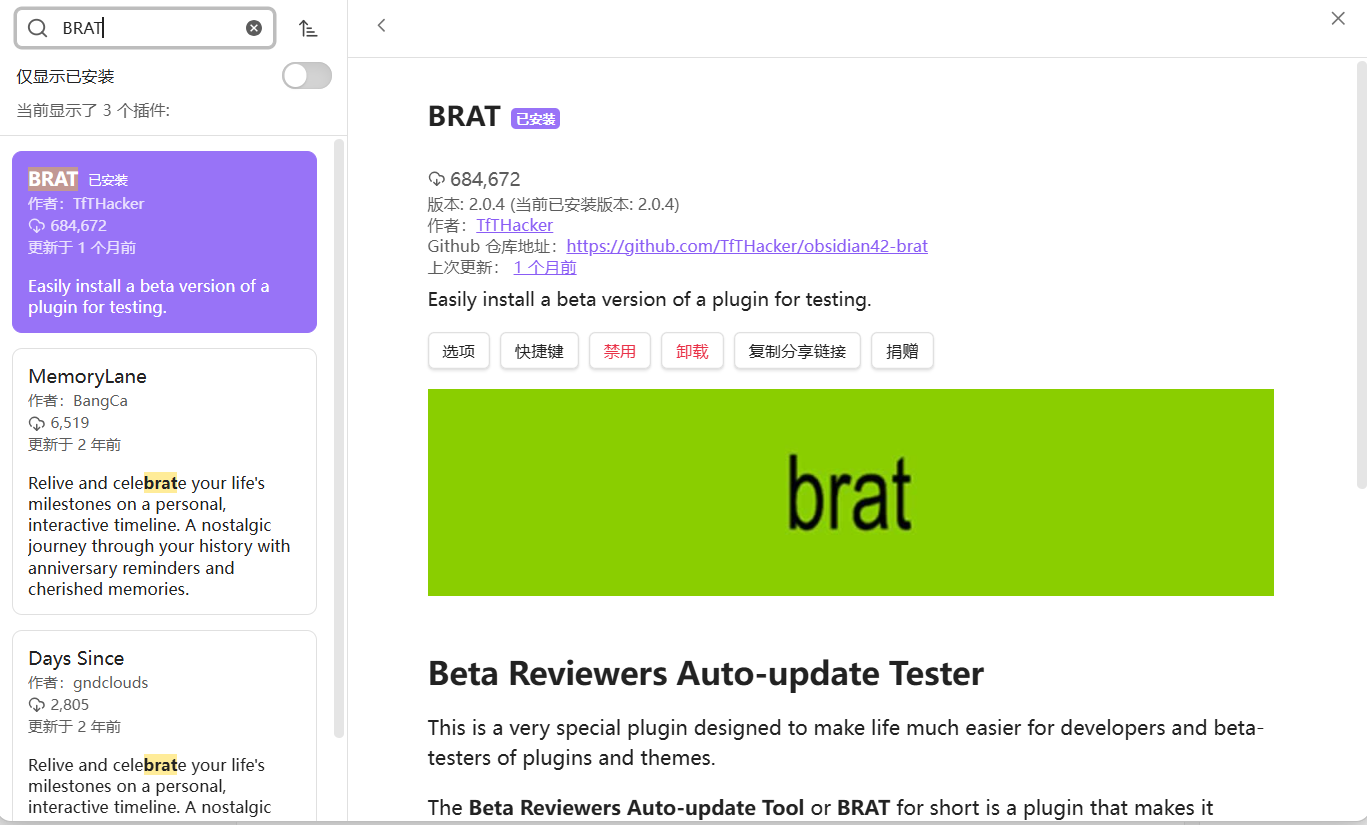
BRAT全称Beta Reviewers Auto-update Tool(Beta测试者自动更新工具),是由开发者TfTHacker开发的Obsidian插件。
BRAT是一个专为开发者和插件/主题测试人员设计的插件,可以轻松安装测试版插件。通过将GitHub存储库路径添加到测试列表中,即可轻松检查更新,下载并重新加载插件,省去了手动创建文件夹、下载文件、复制到正确位置等繁琐步骤。该插件简化了测试过程,解决了开发者和测试人员的繁重工作,提高了工作效率。
在第三方市场插件中搜索BRAT,然后点击安装并启用即可,现在国内网络也能够成功安装插件了
安装好之后,最左侧会出现个笑脸,表示安装成功
- 安装Claudian
Claudian 是一款能将 AI 编程智能体(比如 Claude Code、Codex,以及未来更多的工具)直接嵌入到你 Obsidian 库(Vault)中的插件。你的整个库会直接变成智能体的工作目录——这意味着文件读取与写入、内容搜索、运行 Bash 命令,以及多步骤的复杂工作流,全部都能开箱即用,无缝衔接
安装的方式有很多种:
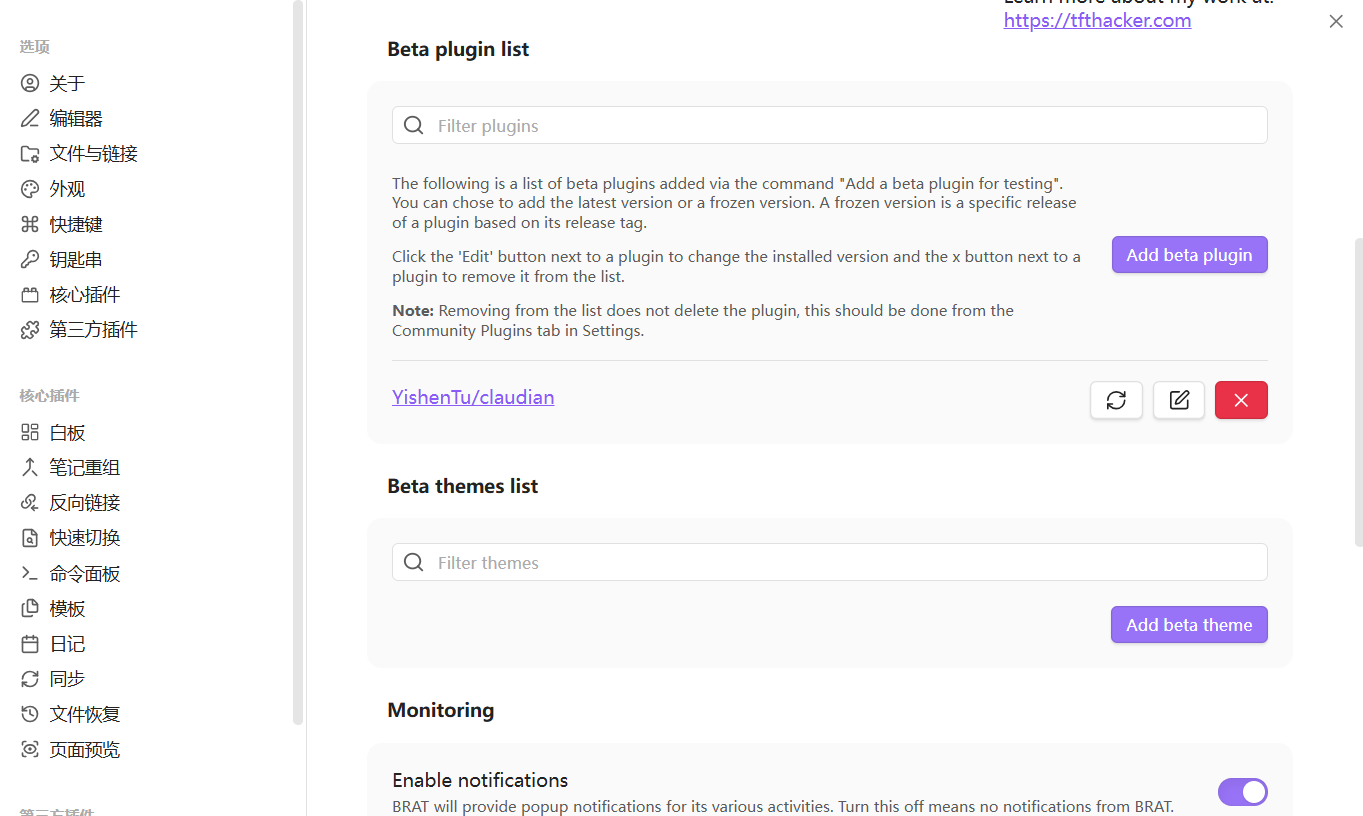
1. 点击左侧笑脸-选择第一个install beta plugin 弹窗出现后在Repository窗口输入 https://github.com/YishenTu/claudian,然后点击`add plugin`即可
2. 在设置-第三方插件-BRAT,进入BRAT管理页面,然后找到Beta Plugin list,点击`Add beta plugin`,会同样弹出输入框,和第一种方法类似,把 https://github.com/YishenTu/claudian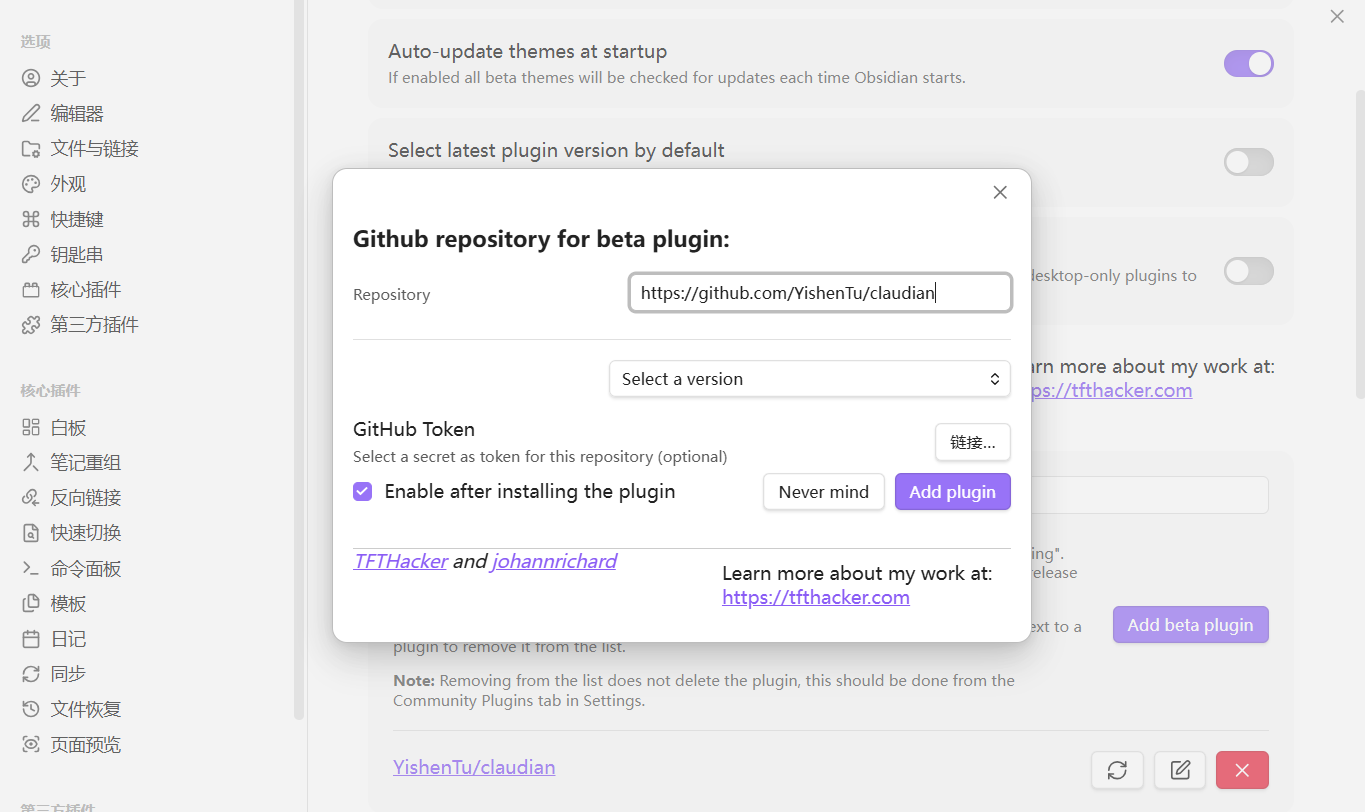
- 激活Claude
核心还是插件能够检测到
Claude CLI否则是无法使用的
安装Claude Code:
Linux/macOS/WSL2 安装可以参考之前的安装教程
Windows用户下可以在
powershell中,输入& ([scriptblock]::Create((New-Object Net.WebClient).DownloadString("https://claude-zh.cn/scripts/install.ps1"))),即可安装成功安装成功后,直接在
C盘----用户----用户名中找到.claude文件夹,新建settings.json文件,输入下面的内容,并把API Key填入即可(模型这里使用的智谱的,可使用该连接https://www.bigmodel.cn/glm-coding?ic=TFCBPKTVRV进行模型code plan的申请)
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "GLM-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "GLM-5",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "GLM-5.1"
}
}不管怎么样激活,都是需要系统先安装
Claude Code,意味着Obsidian必须能够找到Claude CLI的安装,,添加环境变量主要作用只是修改Claudian的模型和显示
Claudian现在已经支持Claude,CodeX和opencode三种平台:
- 直接把系统中的
claude code路径加上去,如果没能自己找到就需要手动添加
- 在环境(Enviroment)中添加一个新的环境,选择平台和输入API Key
ANTHROPIC_API_TOKEN =
ANTHROPIC_BASE_URL = https://open.bigmodel.cn/api/anthropic
ANTHROPIC_DEFAULT_HAIKU_MODEL = glm-4.7
ANTHROPIC_DEFAULT_SONNET_MODEL = glm-5
ANTHROPIC_DEFAULT_OPUS_MODEL = glm-5.1
4. 基础工具使用教程
按照上面的流程安装好Obsidian和Claude Code,以及Claudian插件之后,就可以开始搭建LLMWiki了,下面是一些核心的功能介绍和使用教程
raw笔记 → LLM编译 → 结构化Wiki → 直接塞给LLM
Claudian包含的功能
- Inline Edit(内联编辑): 选中文本或在光标位置使用快捷键,直接在笔记中进行编辑,并支持逐词级别的差异预览
- Slash Commands & Skills(斜杠命令与技能):输入
/或$,可调用可复用的提示模板或技能,支持用户级和知识库(vault)级作用域 @mention(提及功能): 输入@可以引用任何希望代理处理的内容,例如知识库文件、子代理、MCP 服务器或外部目录中的文件- Plan Mode规划模式: 通过
Shift + Tab切换。代理会先进行探索和设计,然后在执行前提交方案供你确认 - Instruction Mode(指令模式 #)
- MCP Servers(MCP 服务器):通过 Model Context Protocol 连接外部工具(支持 stdio、SSE、HTTP)。Claude 在应用内管理知识库 MCP,Codex 使用其 CLI 管理 MCP 配置
- Multi-Tab & Conversations(多标签与会话)
4.1 基础使用方式
- 点击 Obsidian 左侧功能区的
机器人头图标,左侧会弹出Claudian的界面 - 在笔记中选中一段文字,然后在右侧
claudian进行编写 - 会发现
Claudian提醒选中的内容,你可以对选中的两行进行操作
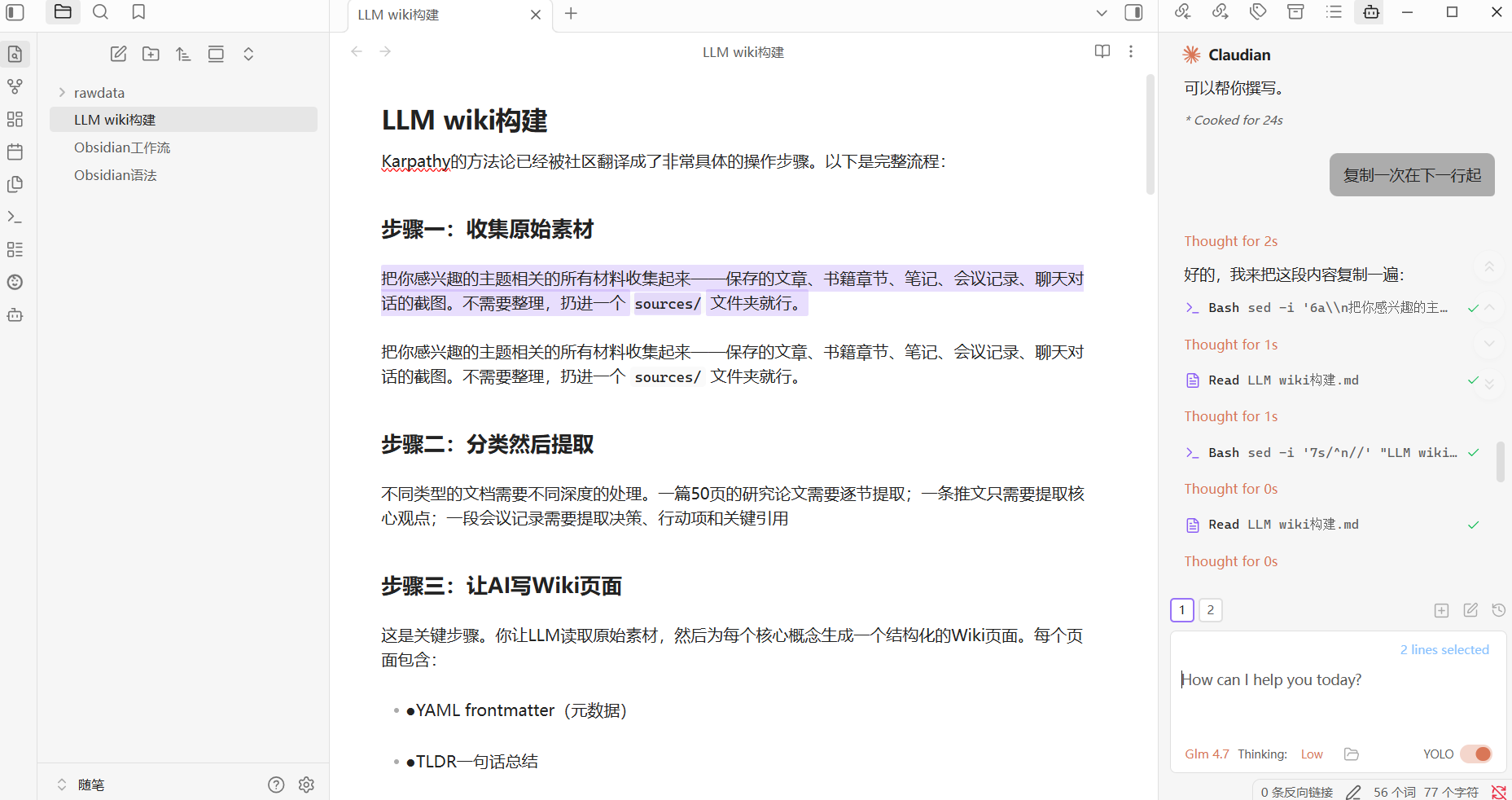
AI 不再是“给你建议”,而是“直接帮你改文档”
4.2 SKILLs使用
只要合理使用skills,是能够最大化利用claude+obsidian:
- 重构一篇技术文章
- 拆解复杂概念
- 生成大纲 / TODO / 知识卡片
- 统一文档风格
- 把“零散笔记”整理成“系统知识”
Claudian 最大的亮点之一,就是 完整支持 Claude Code 的 Skills
安装Skills一般有两种方式
- 在obsidian打开的仓库中,显示所有的隐藏文件夹,找到
.claude,点击进去,找到skills。比如要把Obsidian-skills https://github.com/kepano/obsidian-skills 安装到Claudian中,将Obsidian-skillszip文件下载解压之后,把skill中文件夹复制到.claude/skills中即可.当然插件中也能够自己编写skills
相对于本地文件夹,坚果云这种云盘vault,可以把skill同步到每一个电脑
Claudian能够扫描本地Claude Code中的skill,主要是从~/.claude/plugin和~/.claude/skills中扫描,所以也可通过claude code安装skill,从而得到claudian调用
所有的skill使用和claude code中是一样的,
/skills names即可调用
4.3 Obsidian web clipper使用
Obsidian web clipper是用来剪藏网页,当浏览到感兴趣的内容后,使用浏览器插件,或者在iOS safari中使用插件,一键将内容保存到自己的Obsidian 文件夹中,让你的知识不再凌乱,查找时不再忘了从哪里看到
- Obsidian web clipper安装请查看obsidian web clipper安装教程
- Obsidian 网页剪藏器,阅读器,高亮,解释器,模板,变量,过滤器等使用,请查看相关介绍
5. LLM Wiki使用
LLM Wiki 是由 AI 先驱 Andrej Karpathy 提出的一种颠覆性个人知识管理范式。它摒弃了传统的 RAG(检索增强生成,即每次查询时从零查找拼接),转而让 AI 充当“全职笔记管理员”,将零散资料预先“编译”并持续更新为结构化、互相引用的 Markdown 维基百科
5.1 RAG的背景
过去两年,RAG(Retrieval-Augmented Generation)几乎成了 LLM 应用的”标配”。无论是企业知识库、智能客服还是个人笔记系统,大家的第一反应都是:把文档切块 → 向量化 → 存入向量数据库 → 查询时检索 → 拼进 Prompt。
文档/PDF/网页
↓
文本提取
↓
文本切分(Chunk)
↓
Embedding模型
↓
向量(Vector)
↓
向量数据库存储
↓
语义检索与问答RAG流程缺陷:
- 分块损失:一篇结构化的论文,切成 512 token 的碎片后,上下文关系全丢了
- 检索不稳定:Embedding 相似度并不等于语义相关度,换个说法就可能检索不到
- 同一份文档,每次查询时 LLM 都要重新”阅读”原文,浪费算力
- 原始文档之间没有显式关联,知识只是”堆”在数据库里
简单理解就是: 把文件分解为向量存在向量库之后,每次查询都要重新阅读一遍,而且没有关联,只是堆在一起
5.2 LLM Wiki的背景
放弃查询时才从原始文档中检索的做法,让 LLM逐步构建和维护一个持久化的 wiki,一组结构化、相互链接的 Markdown 文件(一种轻量级的纯文本格式,可以用任何编辑器打开),作为你和原始资料之间的中间层。当你添加新资料时,LLM 不会只是把它索引起来留待日后检索,它会阅读、提取关键信息、整合进现有 wiki,更新实体页面、修订主题摘要、标注新数据与旧结论的矛盾之处、用新证据去强化或推翻已有的综合判断。知识被编译一次就沉淀下来、持续更新,不用每次查询时从头推导
wiki 是一个持久的、不断复利增长的产物. LLM 负责编写和维护全部内容。人负责的是资料筛选、探索方向和提出正确的问题。LLM 做所有苦力活——总结、交叉引用、归档和 bookkeeping(指维护知识库一致性所需的大量琐碎更新工作,如同记账),这些工作才是让知识库随着时间推移真正有用的关键。
Andrej Kaparthy 举了几个简单的例子:
- 个人领域:追踪你自己的目标、健康、心理、自我提升——归档日记、文章、播客笔记,随着时间构建一幅关于你自己的结构化全景
- 研究领域:在数周或数月内深入一个课题——阅读论文、文章、报告,逐步构建一个带有演进论点的综合性 wiki。
- 阅读一本书:逐章归档,为人物、主题、情节线索建立页面,标注它们之间的关联。读完后你就拥有了一部丰富的伴读 wiki。
- 商业/团队:由 LLM 维护的内部 wiki,输入来源是 Slack 讨论、会议记录、项目文档、客户通话。可以有人类参与审核更新。wiki 之所以能保持更新,是因为 LLM 承担了团队中没人愿意做的维护工作。
- 竞争分析、尽职调查、旅行规划、课程笔记、爱好深挖——任何你在持续积累知识并希望它被组织起来而非散落各处的场景。
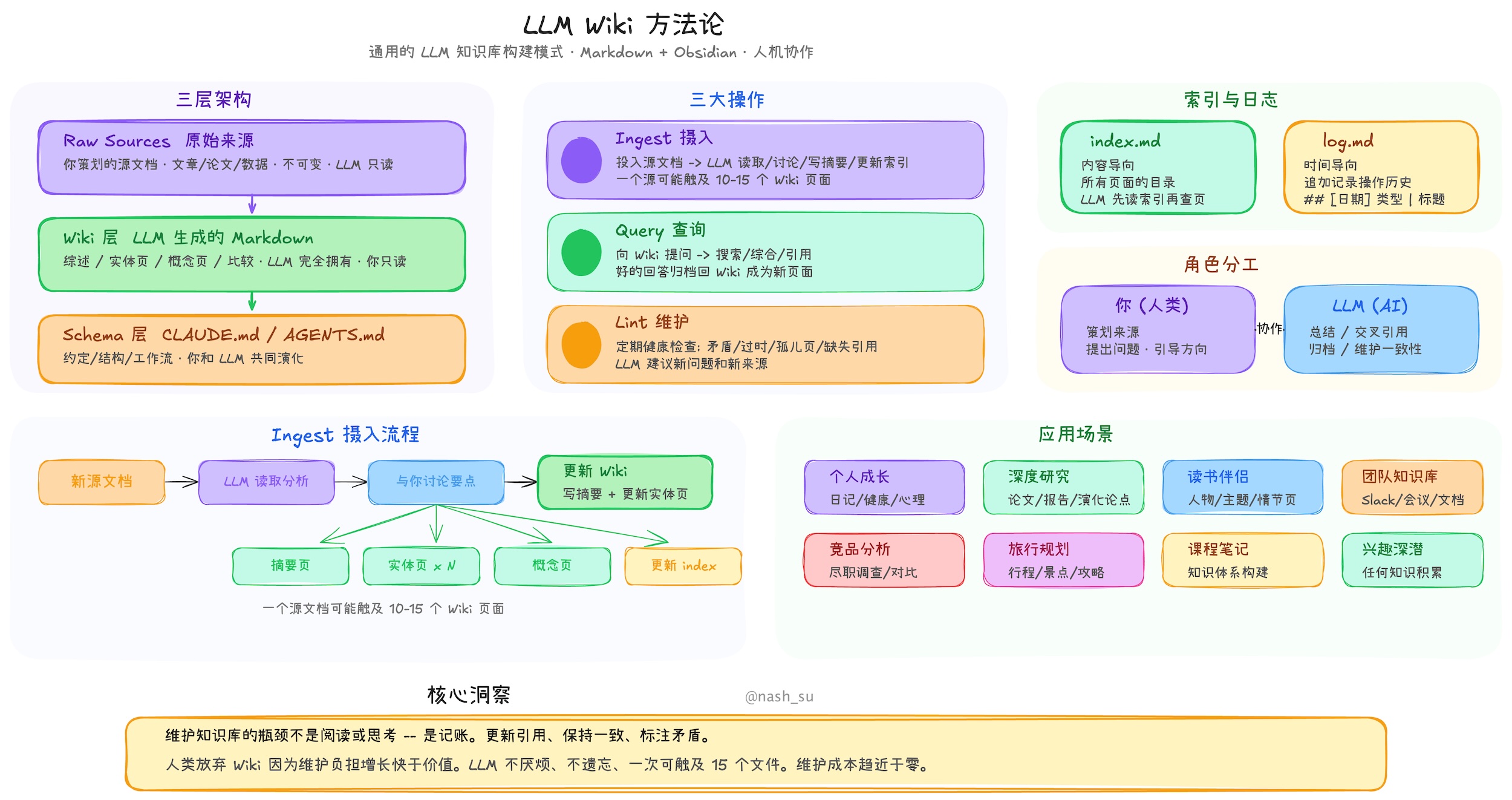
5.3 LLM Wiki 架构
主要分成三层
原始资料源(Raw Sources) – 精心筛选的源文档集合。文章、论文、图片、数据文件。这些是只读的——LLM 从中读取但绝不修改,原始资料永远保持原样。这是你的权威来源
Wiki – 一个由 LLM 生成的 Markdown 文件目录。摘要、实体页面、概念页面、对比分析、概览、综合判断。这一层完全由 LLM 拥有。它创建页面、在新资料到达时更新页面、维护交叉引用、保持一切一致, 你负责阅读,LLM 负责写。
Schema(模式定义) ——一份配置文档(例如 Claude Code 的 CLAUDE.md 或 OpenAI Codex 的 AGENTS.md——这些是各家 AI 编程工具的项目配置文件,告诉 AI 该遵循什么规则),定义 wiki 的结构是怎样的、约定是什么、在摄入资料、回答问题或维护 wiki 时应遵循什么工作流。这是关键配置文件——它让 LLM 成为一个有纪律的 wiki 维护者,而非一个通用聊天机器人。随着你对自己领域的理解加深,你和 LLM 会一起迭代这份文档,让它越来越好用。
5.4 LLM Wiki操作逻辑
摄入(Ingest): 你把新资料放进原始资料集,然后让 LLM 处理它。一个典型流程:LLM 阅读资料,与你讨论关键要点,在 wiki 中写一个摘要页面,更新索引,更新 wiki 中相关的实体和概念页面,并在日志中追加一条记录。一个资料源可能触及 10-15 个 wiki 页面. 个人偏好逐条摄入资料并全程参与——我读摘要、检查更新、引导 LLM 强调什么。但你也可以批量摄入大量资料,减少监督。怎么做取决于你自己,找到适合你的工作流后,记在 Schema 里,下次开新会话时 LLM 就能沿用
查询(Query): 你针对 wiki 提问。LLM 搜索相关页面、阅读它们、综合出带引用的答案。答案可以根据问题采取不同形式——一个 Markdown 页面、一个对比表格、一套幻灯片(Marp,一种把 Markdown 转成演示文稿的工具)、一张图表(matplotlib,Python 制图库)、一个画布。
好的答案可以作为新页面归档回 wiki, 请求的一次对比分析、一个分析结论、你发现的一个关联,这些都值得留下来,不应该消失在聊天历史中。这样,你的探索就像摄入的资料源一样,在知识库中实现复利增长
- 检查(Lint——借用编程术语,原指代码静态检查工具,这里指对知识库做系统性的健康检查)。定期让 LLM 对 wiki 做健康检查。寻找:页面之间的矛盾、已被更新资料取代的过时论断、没有任何入站链接的孤儿页面(orphan pages,即没有其他页面链接到它的”孤岛”页面)、被提及但缺少独立页面的重要概念、缺失的交叉引用、可以通过网络搜索填补的数据缺口。LLM 擅长建议新的调查问题和新的资料来源。这让 wiki 在增长过程中保持健康。
随着Wiki的不断扩充,有两个特殊文件可以帮助LLM(以及您)更好地浏览Wiki。它们各有不同的用途
index.md: 它是 wiki 中所有内容的目录——每个页面列出链接、一行摘要,以及可选的元数据(如日期或资料源计数)。按类别组织(实体、概念、资料源等)。LLM 在每次摄入时更新它。回答查询时,LLM 先读索引找到相关页面,再深入查看。这在中等规模(约 100 个资料源、数百个页面)下效果出奇地好,避免了基于 embedding(嵌入向量,一种把文本转成数字向量以便计算相似度的技术)的 RAG 基础设施的需求
log.md: 它是一个只追加的记录(append-only,只增不改不删),记录发生了什么以及何时发生——摄入、查询、检查。一个实用技巧:如果每条记录以统一的前缀开头(例如## [2026-04-02] ingest | Article Title),日志就可以用简单的 Unix 命令行工具解析——
grep "^## \[" log.md | tail -5就能给你最后 5 条记录。日志给你 wiki 演进的时间线,帮助 LLM 了解最近做了什么。
5.5 LLM wiki工具
5.5.1 QMD 搜索引擎
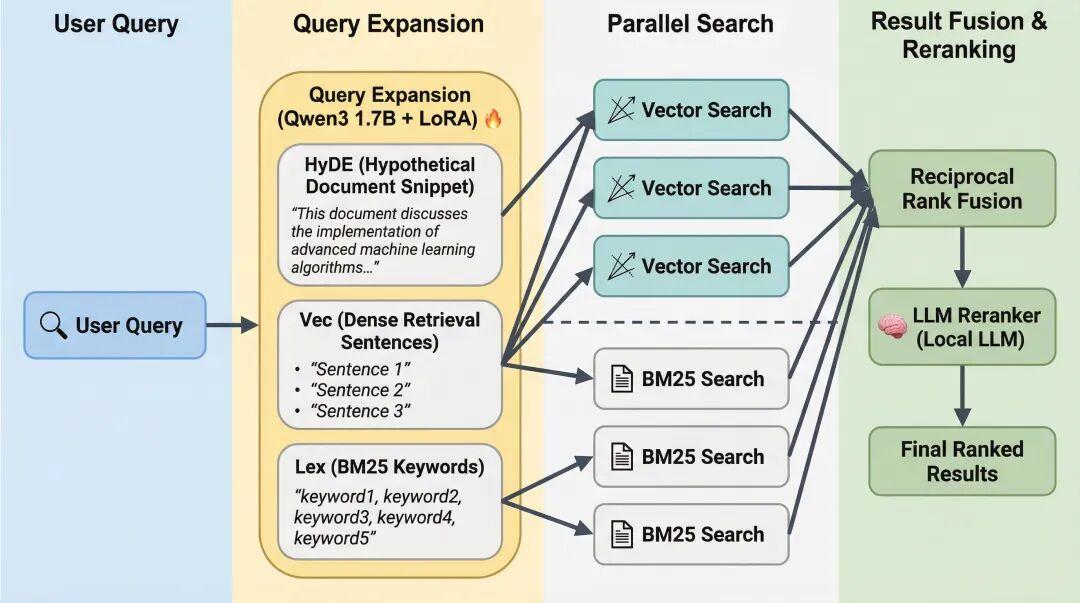
wiki 页面搜索引擎——在小规模下索引文件就够用了,但随着 wiki 增长,你需要正式的搜索能力。
- qmd 是个不错的选择:它是一个本地 Markdown 文件搜索引擎,支持 BM25/向量混合搜索(BM25 是经典的关键词匹配算法,向量搜索则通过语义相似度匹配,混合使用兼顾精确匹配和语义理解)和 LLM 重排序,全部在本地设备上运行
1. 安装
# 使用 npm
npm install -g @tobilu/qmd
# 或使用 Bun(更快)
bun install -g @tobilu/qmd
# 不想安装?直接用 npx 跑
npx @tobilu/qmd --version2. 创建集合
collection本质上是一个路径别名,方便后续搜索时指定范围。
# 索引你的笔记目录
qmd collection add ~/notes --name notes
# 再索引会议记录
qmd collection add ~/Documents/meetings --name meetings
# 查看已创建的集合
qmd collection list3. 添加上下文
context是搜索时使用的额外信息,例如当前日期、时间、地点、任务等。这些信息会自动添加到搜索结果中,帮助 LLM 更好地理解上下文。
# 告诉 QMD 这些目录是什么内容
qmd context add qmd://notes "个人笔记和技术想法"
qmd context add qmd://meetings "团队会议记录和决策"4. 生成嵌入
嵌入是为所有集合生成向量索引,首次运行会自动下载模式,缓存到本地,后续使用无需重复下载
qmd embed5. 搜索
# 关键词搜索(快,适合精确匹配)
qmd search "认证流程"
# 语义搜索(慢,但能理解你的意图)
qmd vsearch "用户怎么登录"
# 混合搜索(推荐,结合两者优势)
qmd query "季度规划会议说了什么" -c meetings
# 只看文件名,不显示具体内容
qmd query "错误处理" --files
# Get a specific document
qmd get "meetings/2024-01-15.md"
# Get a document by docid (shown in search results)
qmd get "#abc123"
# Get multiple documents by glob pattern
qmd multi-get "journals/2025-05*.md"
# Search within a specific collection
qmd search "API" -c notes
# Export all matches for an agent
qmd search "API" --all --files --min-score 0.3将QMD搜索引擎链接AI才能发挥最大的功效
QMD 的
--json和--files输出格式是为Agent工作流设计的
# Get structured results for an LLM 结构性输出
qmd search "authentication" --json -n 10
# List all relevant files above a threshold,设置一个阈值
qmd query "error handling" --all --files --min-score 0.4
# Retrieve full document content 返回所有满足条件的结果
qmd get "docs/api-reference.md" --full- 集成到Claude Code使用MCP
虽然告诉AI在命令行中使用qmd即可运行,但是还是公开了一个MCP接口,方便集成到Claude Code中
自动配置
在终端命令行中执行下面的命令,安装插件系统
claude plugin marketplace add tobi/qmd
claude plugin install qmd@qmd手动配置
在~/.claude/settings.json修改配置文件
{
"mcpServers": {
"qmd": {
"command": "qmd",
"args": ["mcp"]
}
}
}- 使用
在文件夹中启动claude code,在新的文件夹中进行三步即可,让AI帮你解决
❯ 在一个新的文件夹里面需要吗
⏺ 需要。在新文件夹里要三步:
# 1. 添加集合
qmd collection add /path/to/新文件夹 --name 集合名
# 2. 建立文本索引
qmd update
# 3. 生成向量嵌入
qmd embed
或者你也可以让我来做,告诉我文件夹路径和想要的集合名就行。- 后台守护模式
# 启动守护进程,保持模型加载状态
qmd daemon start
# 搜索(速度更快,无需重复加载模型)
qmd query "认证流程" --daemon
# 停止守护进程
qmd daemon stopqmd会从hugging face下载模型,可以将镜像源更改,方便国内的下载
# 临时设置镜像环境变量(仅在当前终端窗口生效)
export HF_ENDPOINT=https://hf-mirror.com
# 建议同时写入配置文件,避免每次重启终端都要重新设置
echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
source ~/.bashrc如果有显卡,可以使用GGML_CUDA=1 qmd pull强制使用显卡
5.5.2 插件工具
- Obsidian Web Clipper
- 把图片下载到本地。在 Obsidian 的设置 → 文件和链接中,把”附件文件夹路径”设为一个固定目录(如raw/assets/)
- Obsidian 的图谱视图(Graph View,以节点和连线的方式可视化所有笔记之间的链接关系)是查看 wiki 全貌的最佳方式——什么和什么连接在一起,哪些页面是枢纽,哪些是孤儿。
- Marp是一种基于 Markdown 的幻灯片格式。Obsidian 有它的插件。用于直接从 wiki 内容生成演示文稿-
- Dataview是一个 Obsidian 插件,可以对页面的 frontmatter(YAML 格式的元数据头,写在 Markdown 文件最顶部,用于存储标签、日期等结构化信息)运行查询。如果你的 LLM 在 wiki 页面中添加了 YAML frontmatter,Dataview 可以生成动态表格和列表
- github
5.6 llm_wiki软件
LLM Wiki 是一个跨平台桌面应用,能将你的文档自动转化为有组织、相互关联的知识库。与传统 RAG(每次查询都从头检索和回答)不同,LLM 会从你的资料中增量构建并维护一个持久化的 Wiki。知识只编译一次并持续更新,而非每次查询都重新推导。
本项目基于 Karpathy 的 LLM Wiki 方法论 —— 一套使用 LLM 构建个人知识库的方法论。我们将其核心理念实现为一个完整的桌面应用,并做了大量增强。
是从命令行转移到了桌面应用,类似Obsidian+Claude Code的集成
- 三栏布局:知识树 / 文件树(左)+ 聊天(中)+ 预览(右)
- 图标侧边栏 —— 在 Wiki、资料源、搜索、图谱、Lint、审核、深度研究、设置之间快速切换
- 自定义可调面板 —— 左右面板支持拖拽调整大小,带最小/最大约束
- 活动面板 —— 实时处理状态,逐文件显示摄入进度
- 全状态持久化 —— 对话、设置、审核项、项目配置在重启后保持
- 场景模板 —— 研究、阅读、个人成长、商业、通用 —— 每个模板预配置 purpose.md 和 schema.md